
Text Mining and Predictive Models
Advances
in storage capabilities, huge data collections, and easy access to target data left
people in an immense data pool. One of the most important ways to deal with
this problem is Data Mining. Data mining is the analysis process of discovering
knowledge in a database. However, according to research by Merrill Lynch and
Gartner, 85-90% of the data all over the world are stored in unstructured form
(McKnight, 2005), and thus, data mining algorithms are not enough by
themselves. At this point Text Mining plays an important role.
Text mining is the process of
exploring structured data and extracting useful information from a collection
of unstructured data. Text mining methods can be used in very different areas
including business documents, customer reviews, web pages, e-mails and other
sources.
One of the most popular text
mining techniques is predictive modeling. Decision trees, neural networks and
boosted trees are different types of predictive models. Predictive models are
used to determine which class a set of data belongs to. For example, a
technology company can apply predictive modeling algorithms to specifically
target customers, and so before generating a new model.

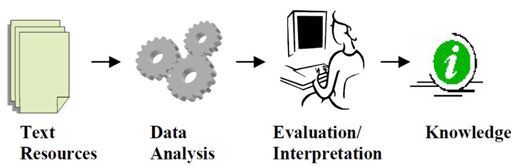
Figure-1: Text mining Process
By using the methods of data mining, choosing this regular
data through piles of unstructured dispersed data is becoming very important.
Text and data mining are similar at the point that both try to obtain
information from massive and unstructured sources.
However, text mining is
based on text sources (Chang,
Healey, McHugh, Wang, Jason, 2001), (Kroeze &
Bothma, 2007). Rregular structured data are extracted from unstructured
data (text) and thus hidden information is discovered. This process is done
with a variety of text mining techniques. (Kroeze & Bothma, 2007)
Natural
language processing (NLP) is a sub-discipline
of computer science and linguistics. In NLP, natural language texts and/or
sounds carried out on the studies in
computer processing. Therefore, modern statistical NLP algorithms require
using of linguistics, computer science, and statistics (Charniak,
1984). All programming languages used around the world have specific
structures, rules, and a standard filed. Natural languages cannot be
explained so easily. All around the globe, there
are hundreds of different official/known languages and each language has more
than 100,000 words. In addition, the fact that language courses are
always changing and expanding with a lot of uncertainty, and each language has
its own unique grammar structure. For this
reason, it is impossible a text mining software to interpret a language 100%
correctly (Erol, 2009).
Text
mining Process (see Figure-1) (Stavrianou, Andritsos, & Nicoloyannis, 2007) is
divided into four main categories: text classification
or text categorization (TC), association analysis, clustering and information extraction (IE). The classification or TC
process is to include categories or classes
of objects previously known. Association analysis
is used to identify the words which are often associated with each other or developing
and to make the sets of documents or the
contents of documents more understandable. IE techniques
are used to find the useful data in the documents
or statements. Cluster analysis is used to discover the underlying structure of the document sets.
1- Chang, G., Healey, M.J., McHugh, J.A.
& Wang, Jason T.L. (2001). Book: Mining the World Wide Web, An information
Search Approach.
2- Kroeze, J.H. & Bothma, T.J.D., (Department of Informatics, M.C. Matthee,Department of
Informatics, Department of Information Science,
University of Pretoria, Pretoria). (2007). Differentiating between data-mining and text-mining terminology
3- Charniak, Eugene:
Introduction to artificial intelligence, page 2. Addison-Wesley, 1984.
4- Erol, U. (2009). Article: “What is Text Mining?”. From http://www.metinmadenciligi.com .
5- Stavrianou, A., Andritsos,
P., & Nicoloyannis, N. (2007). Overview
and semanticissues of text mining. ACM SIGMOD Record, 36(3):23–34
6- McKnight, Radicati, S. & Hoang, Q. (2011). Email Statistics Report 2011-2015. The Radicati Group, Inc. A Technology Market
Research Firm. From
Ahmet,
ReplyDeleteGreat post. Thanks for sharing.
Fadel
I think that thanks for the valuabe information and insights you have so provided here. artificial intelligence
ReplyDelete