Hi guy, Hope you have a good weekend.
Since in the Thursday course, the program failed,
so I referred to “ Amazon Elastic MapReduce Developer Guide”, and tried couple of
times, eventually it worked out. I’d like share my experience with you.
Assuming you guys have downloaded the input.txt
and wordsplitter.py from Ta’s bucket.
1: To create input folder in Amazon S3
I create wc1 folder first, then create input folder in the
wc1 folder.

2: upload input.txt and wordsplitter.py
to an Amazon S3 bucket
The input.txt
is uploaded under the folder of szl0007/wc1/input
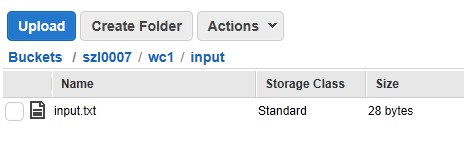
The wordsplitter.py
is under the folder of szl0007/wc1

3 To launch the Amazon EMR job flow
Click
services and click Elastic MapReduce. or open the Amazon Elastic MapReduce
console at https://console.aws.amazon.com/elasticmapreduce/.

For job flow name you can input whatever you want

Mapper: The wordsplitter.py
is under the folder of szl0007/wc1
Output
location: as long as under the your bucket, it should be fine.

Click continue

Click continue and choose my account as key pair,
then creates logs under my bucket.

click continue

continue
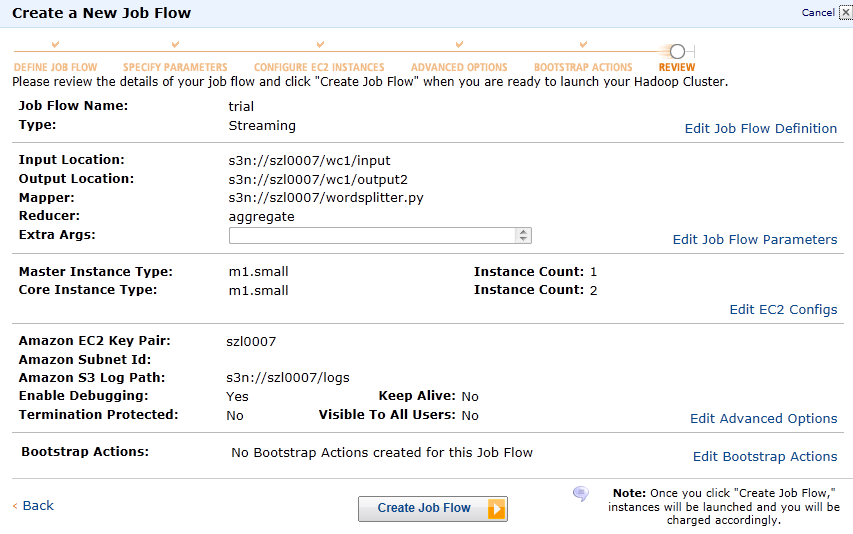
Click Create Job Flow

4 Run the Job Flow
Click View my job flows and check on job flow status




As you can see the states of the program changes
from Starting- Running- Shutting down- Completed, which takes 5-10 minutes in my
computer.
5 View the results
Click Services and go to S3. Find the output2 folder,
download 3 part-00001 2 3,

Use notepad to open them.

Thanks for sharing. I also want to share my experience to use AWS. After a couple of trying, I succeed to see “RUNNING” comment on my AWS window and I realized that I made a mistake to define output file path. Since I thought that we need to create a output file then define the output file to convert to output, I created the output file and wrote the output file path as we did for input file and wordsplitter.py file. Finally, I tried not to define the output and see the results and I was done. Since I thought some people might do the same mistake I wanted to share my failure with you. One more thing I can share here is that since my file was very large about 1.43 GB, in the “ADVANCED OPTIONS” phase, I clicked “No” for Enable Debugging and it took 51 minutes to complete. It was a good experience to see what the AWS is able to do with large files. Even WordPad had a trouble to open my file; AWS was able to count the words in it.
ReplyDeleteShaomao,
ReplyDeleteThanks for sharing. I believe that was helpful for many of us, it also helped Erhan troubleshoot his error.
Also, relevant to this post is the screenshot video from class, see http://www.youtube.com/watch?v=W3X8U-zwOwI&feature=youtu.be
Fadel
https://auburnbigdata.blogspot.com/2013/02/nasa-application-of-big-data.html?showComment=1564726145574#c8835385740851522226
ReplyDelete