Decision Trees are useful techniques for classification, prediction
and fitting data. In this post I demonstrate how to build a basic decision tree
model in RapidMiner.
At first you need to make sure that your data only contains attribute and label types which are allowed in Decision Tree operator. As you
can see in the below figure, the Decision Tree operator just accepts
Polynomial, Numerical and Binomial attributes and Binomial and Polynomial
labels (target attributes). So, if your target data is a numeric variable you may
modify it to the accepted type by categorizing it into several intervals and then
defining dummy binomial attributes for each interval. I explained this process
in my previous post.
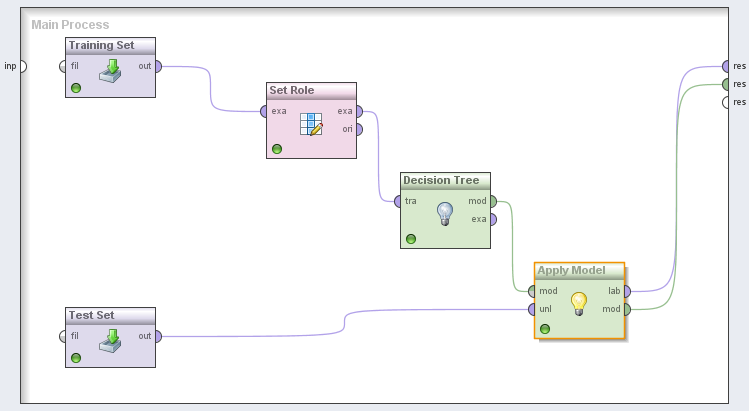
Once you prepared your data based on the allowable attributes and
labels, you are ready to build the model. Add a Read Excel operator and import
your training data set to this operator and then use a Set Role operator to set
the target attribute role to Label and then add a Decision Tree operator.
Connect these operators to each other in the order that you added them to the
model. Your model should looks like the figure below.
Now add the second Read Excel operator to import the test data set.
then add the Apply Model operator and connect its unlabeled port to the out
port of the Read Excel operator for the test data and its model port to the
model port of the Decision Tree operator as illustrated in the figure below.
The Apply model does not accept the data set which has the label attribute. So
if the test data set contains the target attribute, you should eliminate this attribute
and let the RapidMiner to fill out it by itself. As an example, I built a model
based on a data set which contains 5 numeric regular attributes and a target binomial
label which has two values Min and Max. The following figures show the
results.


As you see, RapidMiner has created three attributes which are distinguished
by pink color in Meta Data View window. Because my target label has two possible outputs,
RapidMiner created an attribute for every outputs and calculated their occurrence probabilities for all instances. In the third created
attribute, RapidMiner predicts the output for each instance based on the output probabilities.
The output with the highest probability is the most likely occurring event, so
it is reported as a prediction for that instance. Furthermore in the tab Tree, you
can see the generated decision tree for your problem and analyze it.
In my
model, “3hr sum” and “month sum” attributes are the most affecting attributes
in the model, respectively. In the Text view, you can see the tree summary and
also the branches confidences.






Decision trees are extensively used in decision support systems and also economic decision making, and since Every body including myself prefers using spreadsheets like Excel over rapid miner, I suggest Palisade Precision Tree.(http://www.palisade.com/precisiontree/)
ReplyDeleteyou can find the whole palisade package on any PC in business school labs. Working with this package is way easier than Rapid Miner but obviously slower.
I disagree that "Every body prefers using spreadsheets like Excel over RapidMiner". I love RapidMiner's interface and the different algorithms that you have access to are quite extensive. I have a blog with several RapidMiner tutorials.. http://www.completebusinessanalytics.com
ReplyDelete@mohammadnaser
ReplyDeleteYou are confused, and ill-informed.
I am very familiar with BOTH Palisade's Decision Tree and Rapid Miner.
You are confusing two different tools, which only share the same name.
You are confusing Palisade's Precision Tree which requires 'you', the user, to build a tree-like structure to determine the choice nodes, the probability of each outcome ... and the expected value with each outcome.
It works with 'events' and 'outcomes'. Its purpose is to recommend an optimal course of action.
Rapid Miner is a data mining utility which automatically builds a categorisation structure for data records, to enable automated predicted classification of new data records based on the principals of information gain.
Your comment is misleading and mis-informed.
I suspect you haven't even tried Rapid Miner, let alone understand its purpose.
I really appreciate information shared above. It’s of great help. If someone want to learn Online (Virtual) instructor lead live training in RAPIDMINER kindly contact us http://www.maxmunus.com/contact
ReplyDeleteMaxMunus Offer World Class Virtual Instructor led training on RAPIDMINER We have industry expert trainer. We provide Training Material and Software Support. MaxMunus has successfully conducted 100000+ trainings in India, USA, UK, Australlia, Switzerland, Qatar, Saudi Arabia, Bangladesh, Bahrain and UAE etc.
For Demo Contact us.
Saurabh Srivastava
MaxMunus
E-mail: saurabh@maxmunus.com
Skype id: saurabhmaxmunus
Ph:+91 8553576305 / 080 - 41103383
http://www.maxmunus.com/
Privileged to read this informative blog on Data Science. Commendable efforts to put on research the data. Please enlighten us with regular updates on Data Scinece. Friends if you're keen to know more about Data Science you can watch this amazing AI tutorial on the same.
ReplyDeletehttps://www.youtube.com/watch?v=sg5h_qcuw4k
This comment has been removed by the author.
ReplyDeleteThanks for posting such a great Blog.you done a great job machine learning online training
ReplyDeleteDecision trees are a great flow chart tree structuecire.Yet decision trees are less appropriate for estimation tasks where the goal is to predict the value of a continuous attribute.
ReplyDeleteTo understand futher more lets look at some Decision Tree Examples in the Creately diagram community.